オライリーのPDF書籍をePubに変換する

なんとなく日本語PDFをePub化することができたので、その手順をメモっとく。ただし、以下の方法ソースをベタでイジるので万人にはおすすめできない。
大まかな手順は、
- Calibre最新版をインストール
- Calibreの最新ソースを落としてくる
- poppler(pdftohtmlコマンドが含まれている)の最新版を落としてくる
- xpdf-japanese 言語サポートパッケージを用意する
- Calibreのソースを改変、無理やり日本語対応させる
という感じ
環境は、Mac OS X Snow Leopard 10.6.7
以下、手順の詳細
Calibre最新版をインストール
以下から最新版をダウンロード/インストールする。
calibre - E-book management
このときのバージョンは
$ calibre --version calibre (calibre 0.7.55)
Calibreの最新ソースを落としてくる
ソースコードをいじりたいので、Calibreのソースコードを落としてくる。
Calibreのソースコードの管理にはBazaarを使ってるっぽい。
HomeBrew 経由で Bazaar をインストールして、Calibre のソースコードを落としてくる。
$ brew bazaar $ bzr branch lp:calibre
ソースコードを落としてきたら、ソースコードのパスを環境変数に設定する。例えば以下のような感じ。
$ export CALIBRE_DEVELOP_FROM=/Users/snaka/work/calibre/src/
これで、calibreのコマンドを実行したとき、/Applicationフォルダのほうじゃなくて、CALIBRE_DEVELOP_FROMで指定した先のソースコードを実行してくれるようになる。
詳しくは、以下のページを参照。
Setting up a calibre development environment ― calibre User Manual
Popplerのダウンロード
Calibre は pdftohtml というコマンドを使って PDF を XHTML に変換しているらしい。その pdftohtml コマンドも本家ではなく、Poppler という Xpdf を fork したライブラリに含まれるバージョンのものを前提としている。
Calibreをインストールすると pdftohtml コマンドもインストールできるが、日本語の処理がダメっぽいので、自分で最新の Poppler をインストールする。
これもHomeBrew経由でインストールできる。
$ brew poppler
このときのバージョンは
$ brew info poppler poppler 0.16.3 http://poppler.freedesktop.org/ Depends on: pkg-config /usr/local/Cellar/poppler/0.16.3 (284 files, 18M) http://github.com/mxcl/homebrew/commits/master/Library/Formula/poppler.rb
pdftohtml 及び Poppler プロジェクトについては以下のページを参照
PDFTOHTML conversion program
Poppler
xpdf-japanese 言語サポートパッケージをインストールする
このままだと、pdftohtml 日本語が処理できないので、xpdf-japanese 言語サポートパッケージをダウンロード/インストールする。
上記ページの "Language Support Packages"から、"Japanese"をダウンロード。ダウンロードしたファイルをtarで展開し、適当な場所(REDMEに従えば、/usr/local/share/xpdf/japanese)に格納する。
$ cd ~/work $ wget ftp://ftp.foolabs.com/pub/xpdf/xpdf-japanese.tar.gz $ tar zxvf xpdf-japanese.tar.gz $ cd /usr/local/share $ mkdir xpdf $ cd xpdf $ mkdir japanese $ cd japanese $ cp ~/work/xpdf-japanese/* .
そして、~/.xpdfrc にadd-to-xpdfrcの内容を追加する。
$ cat add-to-xpdfrc >> ~/.xpdfrc
これで、pdftohtmlコマンドで日本語が扱えるようになった。
Calibreのソースを改変して無理やり日本語XHTMLを出力させる
まず、Calibre付属の pdftohtml じゃなく、自分でダウンロードしてきた pdftohtml*1を使うようにするため、calibre/ebooks/pdf/pdftohtml.py を以下のように書き換える。
=== modified file 'src/calibre/ebooks/pdf/pdftohtml.py' --- src/calibre/ebooks/pdf/pdftohtml.py 2011-04-08 23:51:07 +0000 +++ src/calibre/ebooks/pdf/pdftohtml.py 2011-05-01 10:26:15 +0000 @@ -18,8 +18,8 @@ PDFTOHTML = 'pdftohtml' popen = subprocess.Popen -if isosx and hasattr(sys, 'frameworks_dir'): - PDFTOHTML = os.path.join(getattr(sys, 'frameworks_dir'), PDFTOHTML) +#if isosx and hasattr(sys, 'frameworks_dir'): +# PDFTOHTML = os.path.join(getattr(sys, 'frameworks_dir'), PDFTOHTML) if iswindows and hasattr(sys, 'frozen'): PDFTOHTML = os.path.join(os.path.dirname(sys.executable), 'pdftohtml.exe') popen = partial(subprocess.Popen, creationflags=0x08) # CREATE_NO_WINDOW=0x08 so that no ugly console is popped up
あと、出力するXHTMLに lang='ja' と xml:lang='ja' 属性を強制的に追加*2すよう、 calibre/ebooks/oeb/base.py を以下のように書き換える。
=== modified file 'src/calibre/ebooks/oeb/base.py' --- src/calibre/ebooks/oeb/base.py 2011-03-23 04:40:01 +0000 +++ src/calibre/ebooks/oeb/base.py 2011-05-01 10:23:02 +0000 @@ -974,6 +974,10 @@ '') data = data.replace("<?xml version='1.0' encoding='utf-8'??>", '') data = etree.fromstring(data, parser=RECOVER_PARSER) + + data.attrib['lang'] = 'ja' + data.set('{http://www.w3.org/XML/1998/namespace}lang', 'ja') + elif namespace(data.tag) != XHTML_NS: # OEB_DOC_NS, but possibly others ns = namespace(data.tag)
これで、ebook-convert コマンドが日本語PDFに対応できるようになった。
試してみる
ためしに、オライリーの「BINARY HACKS」のサンプルPDFを日本語化してみる。
サンプルPDFのページ:Binary Hacks - サンプルPDF
上記のページからsample.pdfをダウンロードして、以下のコマンドで、そのPDFをePubファイルに変換する。
$ ebook-convert sample.pdf sample.epub
上記コマンドで生成されたePubファイルを Calibre の ePubビューアで開いてみた。以下のように改行の位置とかが気にはなるが、ちゃんと表示できた。
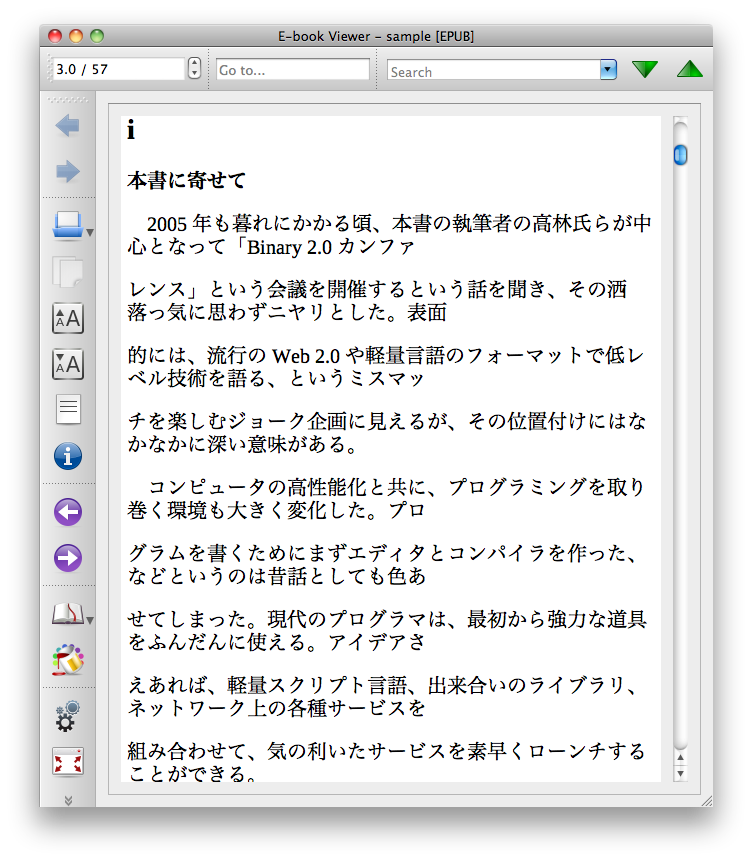

さすがにソースコードの部分とかは読みにくいけど、文章はなんとか読めないことはない。
これで、HDDの中で「積ん読」状態だった、オライリーから買ったPDF本を、ちょっとした合間にiPhoneで読むことができる、かな..?